|
Which Rewards Matter? Reward Selection for Reinforcement Learning under Limited Feedback
Shreyas Chaudhari*,
Renhao Zhang*,
Philip Thomas,
Bruno Castro da Silva.
Preprint
Abstract | arXiv
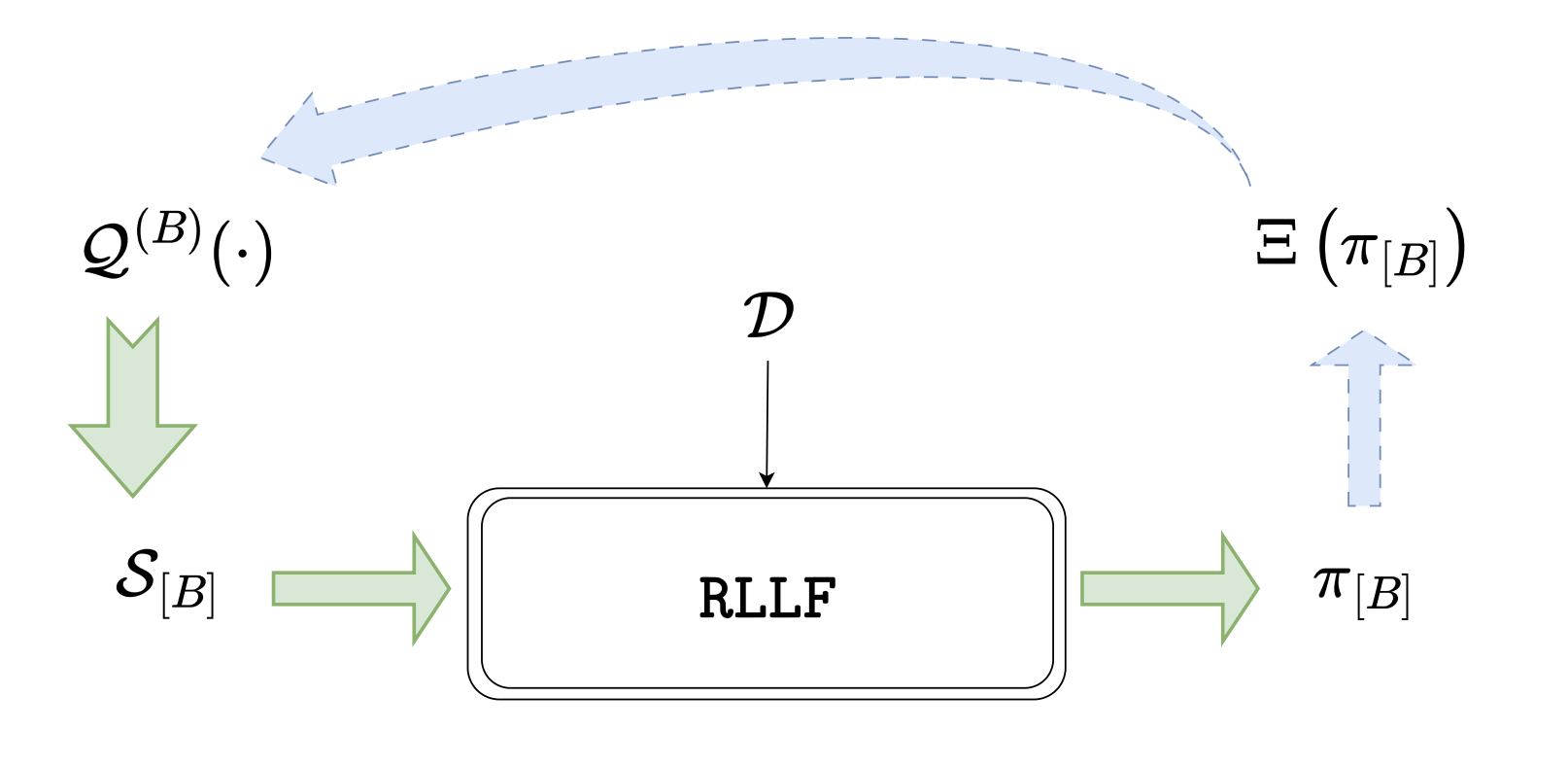
The ability of reinforcement learning algorithms to learn effective policies is determined by the rewards available during training. However, for practical problems, obtaining large quantities of reward labels is often infeasible due to computational or financial constraints, particularly when relying on human feedback. When reinforcement learning must proceed with limited feedback -- only a fraction of samples get rewards labeled -- a fundamental question arises: which samples should be labeled to maximize policy performance? We formalize this problem of reward selection for reinforcement learning from limited feedback (RLLF), introducing a new problem formulation that facilitates the study of strategies for selecting impactful rewards. Two types of selection strategies are investigated: (i) heuristics that rely on reward-free information such as state visitation and partial value functions, and (ii) strategies pre-trained using auxiliary evaluative feedback. We find that critical subsets of rewards are those that (1) guide the agent along optimal trajectories, and (2) support recovery toward near-optimal behavior after deviations. Effective selection methods yield near-optimal policies with significantly fewer reward labels than full supervision, establishing reward selection as a powerful paradigm for scaling reinforcement learning in feedback-limited settings.
|
|
RLHF Deciphered: A Critical Analysis of Reinforcement Learning from Human Feedback for LLMs
Shreyas Chaudhari*,
Pranjal Aggarwal*,
Vishvak Murahari,
Tanmay Rajpurohit,
Ashwin Kalyan,
Karthik Narasimhan,
Ameet Deshpande,
Bruno Castro da Silva.
ACM Computing Surveys 2025
Abstract | Paper
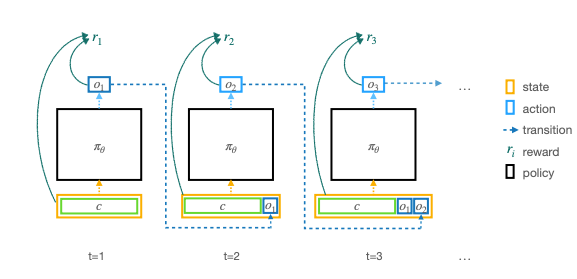
State-of-the-art large language models (LLMs) have become indispensable tools for various tasks. However, training LLMs to serve as effective assistants for humans requires careful consideration. A promising approach is reinforcement learning from human feedback (RLHF), which leverages human feedback to update the model in accordance with human preferences and mitigate issues like toxicity and hallucinations. Yet, an understanding of RLHF for LLMs is largely entangled with initial design choices that popularized the method and current research focuses on augmenting those choices rather than fundamentally improving the framework. In this paper, we analyze RLHF through the lens of reinforcement learning principles to develop an understanding of its fundamentals, dedicating substantial focus to the core component of RLHF -- the reward model. Our study investigates modeling choices, caveats of function approximation, and their implications on RLHF training algorithms, highlighting the underlying assumptions made about the expressivity of reward. Our analysis improves the understanding of the role of reward models and methods for their training, concurrently revealing limitations of the current methodology. We characterize these limitations, including incorrect generalization, model misspecification, and the sparsity of feedback, along with their impact on the performance of a language model. The discussion and analysis are substantiated by a categorical review of current literature, serving as a reference for researchers and practitioners to understand the challenges of RLHF and build upon existing efforts.
|
|
PersonaGym: Evaluating Persona Agents and LLMs
Vinay Samuel,
Henry Peng Zou,
Yue Zhou,
Shreyas Chaudhari,
Ashwin Kalyan,
Tanmay Rajpurohit,
Ameet Deshpande,
Karthik Narasimhan,
Vishvak Murahari.
EMNLP Findings 2025
Abstract | Paper
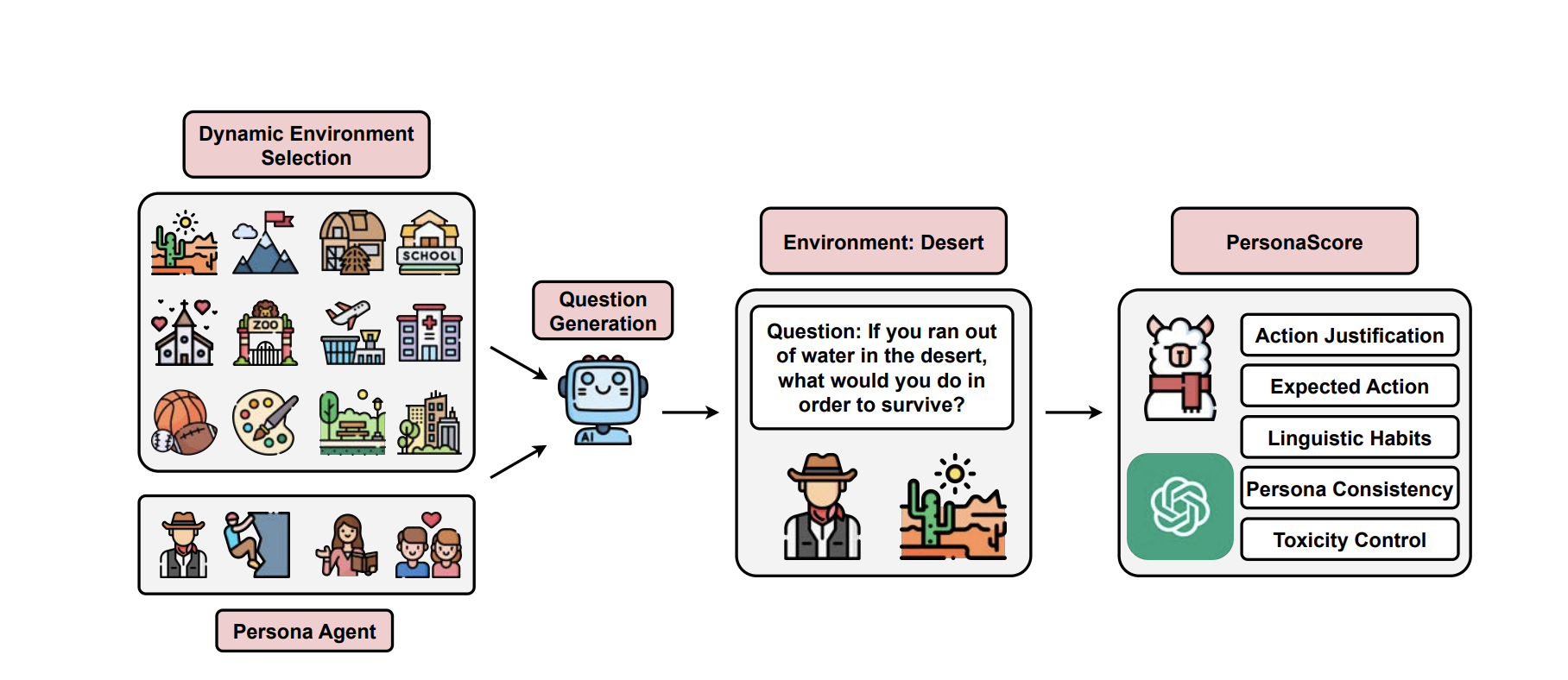
Persona agents, which are LLM agents conditioned to act according to an assigned persona, enable contextually rich and user-aligned interactions across domains like education and healthcare.However, evaluating how faithfully these agents adhere to their personas remains a significant challenge, particularly in free-form settings that demand consistency across diverse, persona-relevant environments.We introduce PersonaGym, the first dynamic evaluation framework for persona agents, and PersonaScore, a human-aligned automatic metric grounded in decision theory that enables comprehensive large-scale evaluation. Our evaluation of 10 leading LLMs across 200 personas and 10,000 questions reveals significant advancement opportunities.For example, GPT-4.1 had the exact same PersonaScore as LLaMA-3-8b despite being a more recent and advanced closed-source model. Importantly, increased model size and complexity do not necessarily enhance persona agent capabilities, underscoring the need for algorithmic and architectural innovation toward faithful, performant persona agents.
|
|
Abstract Reward Processes: Leveraging State Abstraction for Consistent Off-Policy Evaluation
Shreyas Chaudhari,
Ameet Deshpande,
Bruno Castro da Silva,
Philip Thomas.
Thirty-eighth Annual Conference on Neural Information Processing Systems (NeurIPS 2024)
Abstract | Paper | Errata
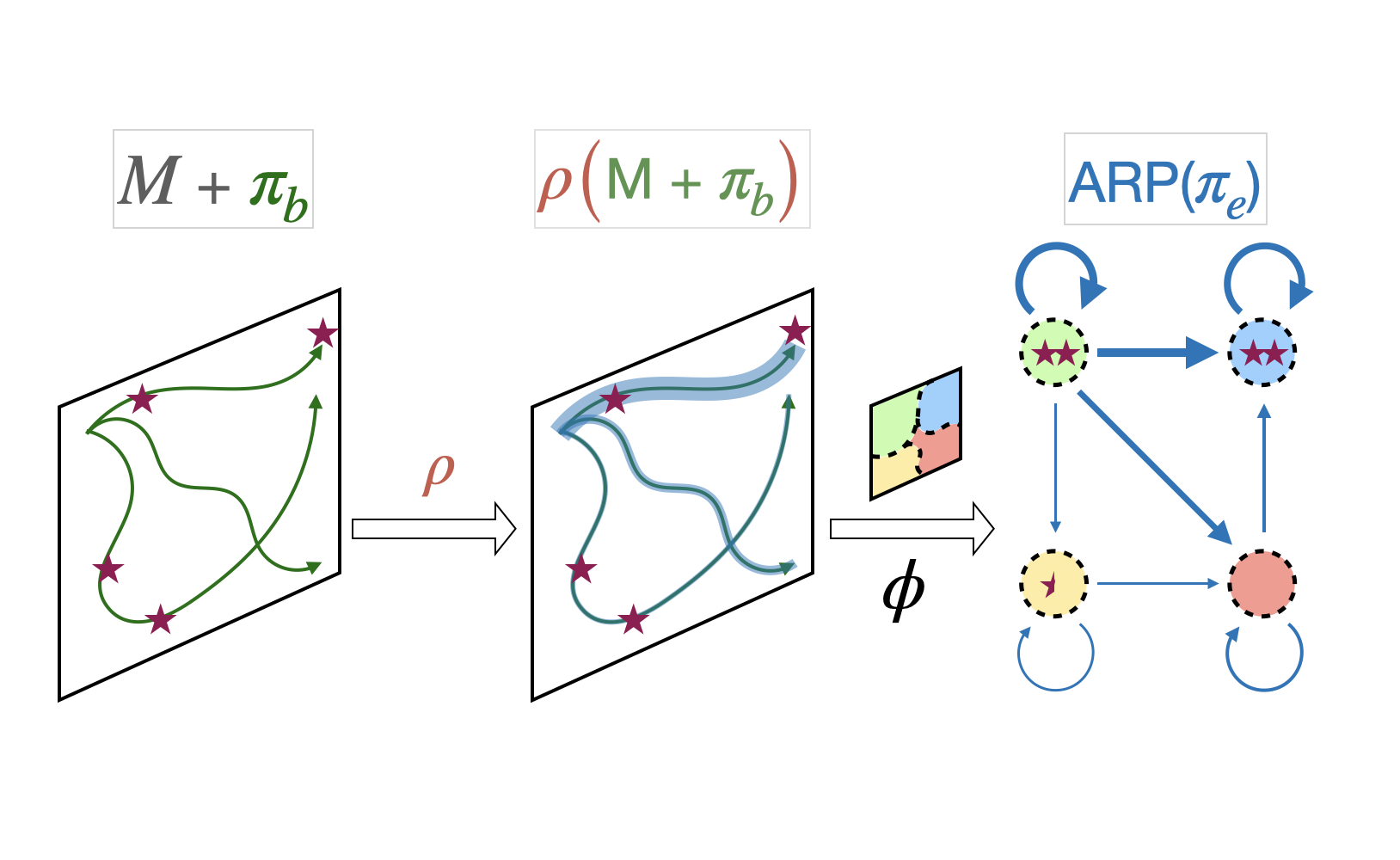
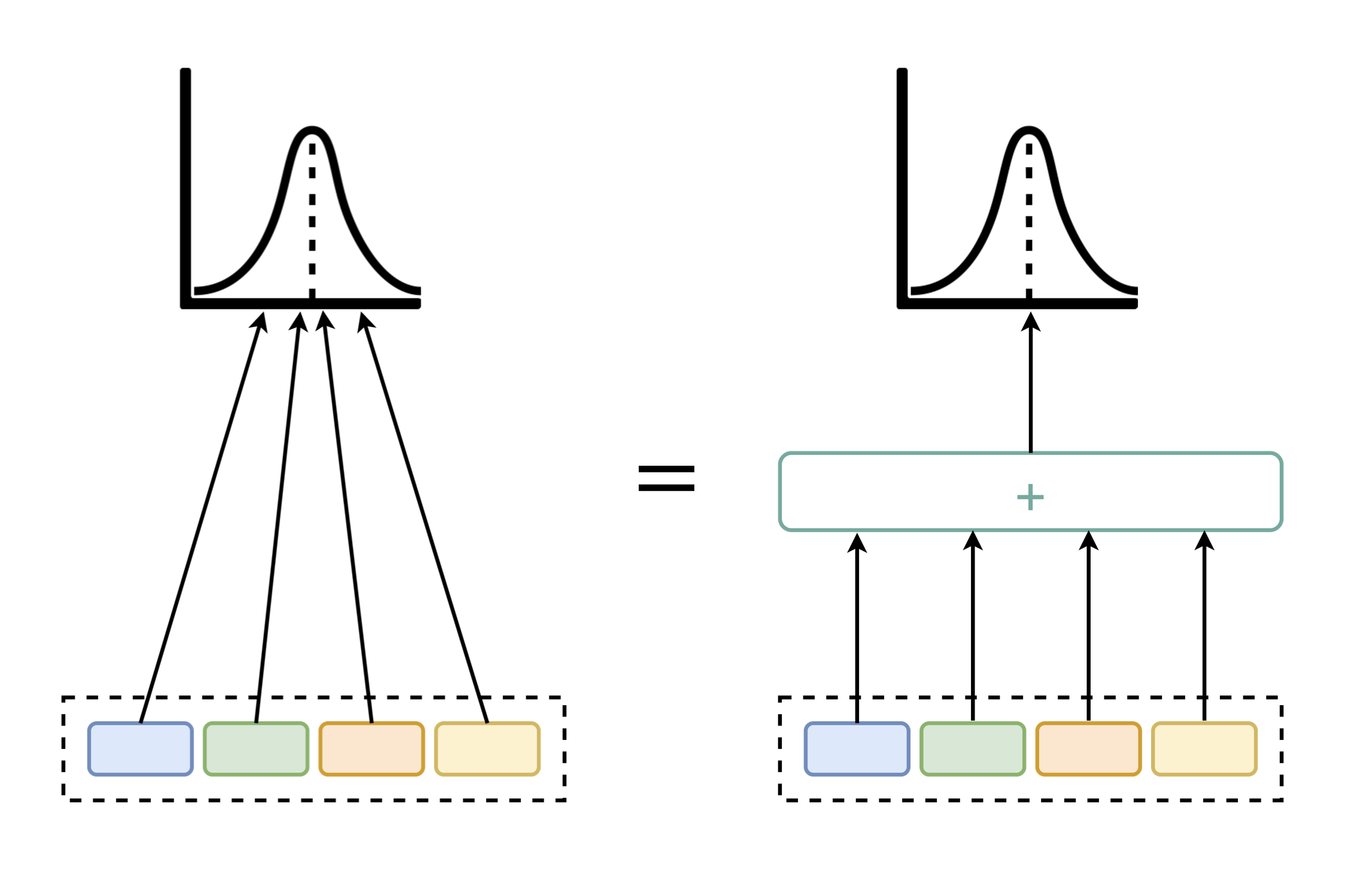
Evaluating policies using off-policy data is crucial for applying reinforcement learning to real-world problems such as healthcare and autonomous driving. Previous methods for off-policy evaluation (OPE) generally suffer from high variance or irreducible bias, leading to unacceptably high prediction errors. In this work, we introduce STAR, a framework for OPE that encompasses a broad range of estimators -- which include existing OPE methods as special cases -- that achieve lower mean squared prediction errors. STAR leverages state abstraction to distill complex, potentially continuous problems into compact, discrete models which we call abstract reward processes (ARPs). Predictions from ARPs estimated from off-policy data are provably consistent (asymptotically correct). Rather than proposing a specific estimator, we present a new framework for OPE and empirically demonstrate that estimators within STAR outperform existing methods. The best STAR estimator outperforms baselines in all twelve cases studied, and even the median STAR estimator surpasses the baselines in seven out of the twelve cases.
|
|
Distributional Off-Policy Evaluation for Slate Recommendations
Shreyas Chaudhari,
David Arbour,
Georgios Theocharous,
Nikos Vlassis.
Thirty-Eighth AAAI Conference on Artificial Intelligence (AAAI-24)
Abstract | Paper
Recommendation strategies are typically evaluated by using previously logged data, employing off-policy evaluation methods to estimate their expected performance. However, for strategies that present users with slates of multiple items, the resulting combinatorial action space renders many of these methods impractical. Prior work has developed estimators that leverage the structure in slates to estimate the expected off-policy performance, but the estimation of the entire performance distribution remains elusive. Estimating the complete distribution allows for a more comprehensive evaluation of recommendation strategies, particularly along the axes of risk and fairness that employ metrics computable from the distribution. In this paper, we propose an estimator for the complete off-policy performance distribution for slates and establish conditions under which the estimator is unbiased and consistent. This builds upon prior work on off-policy evaluation for slates and off-policy distribution estimation in reinforcement learning. We validate the efficacy of our method empirically on synthetic data as well as on a slate recommendation simulator constructed from real-world data (MovieLens-20M). Our results show a significant reduction in estimation variance and improved sample efficiency over prior work across a range of slate structures.
|
|
From Past to Future: Rethinking Eligibility Traces
Dhawal Gupta,
Scott Jordan,
Shreyas Chaudhari,
Bo Liu,
Philip Thomas,
Bruno Castro da Silva.
Thirty-Eighth AAAI Conference on Artificial Intelligence (AAAI-24)
Abstract | Paper
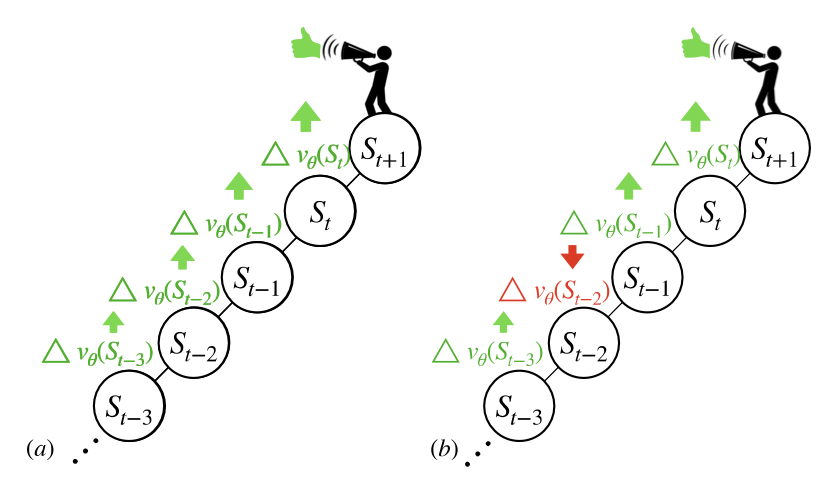
In this paper, we introduce a fresh perspective on the challenges of credit assignment and policy evaluation. First, we delve into the nuances of eligibility traces, and explore instances where their updates may result in unexpected credit assignment to preceding states. From this investigation emerges the concept of a novel value function, which we term as the bidirectional value function. Unlike traditional state value functions, bidirectional value functions account for both future expected returns (rewards anticipated from the current state onward) and past expected returns (cumulative rewards from the episode's start to the present). We derive principled update equations to learn this value function and, through experimentation, demonstrate its efficacy in enhancing the process of policy evaluation. In particular, our results indicate that the proposed learning approach can, in certain challenging contexts, outpace the TD($\lambda$) method that learns $v^\pi$ directly. Overall, our findings present a new perspective on eligibility traces, and potential advantages to the novel value function it inspires, especially for policy evaluation.
|
|
Learning Models and Evaluating Policies with Offline Off-Policy Data under Partial Observability
Shreyas Chaudhari,
Philip Thomas,
Bruno Castro da Silva.
Adaptive Experimental Design and Active Learning in the Real World Workshop at NeurIPS 2023
Abstract | Paper
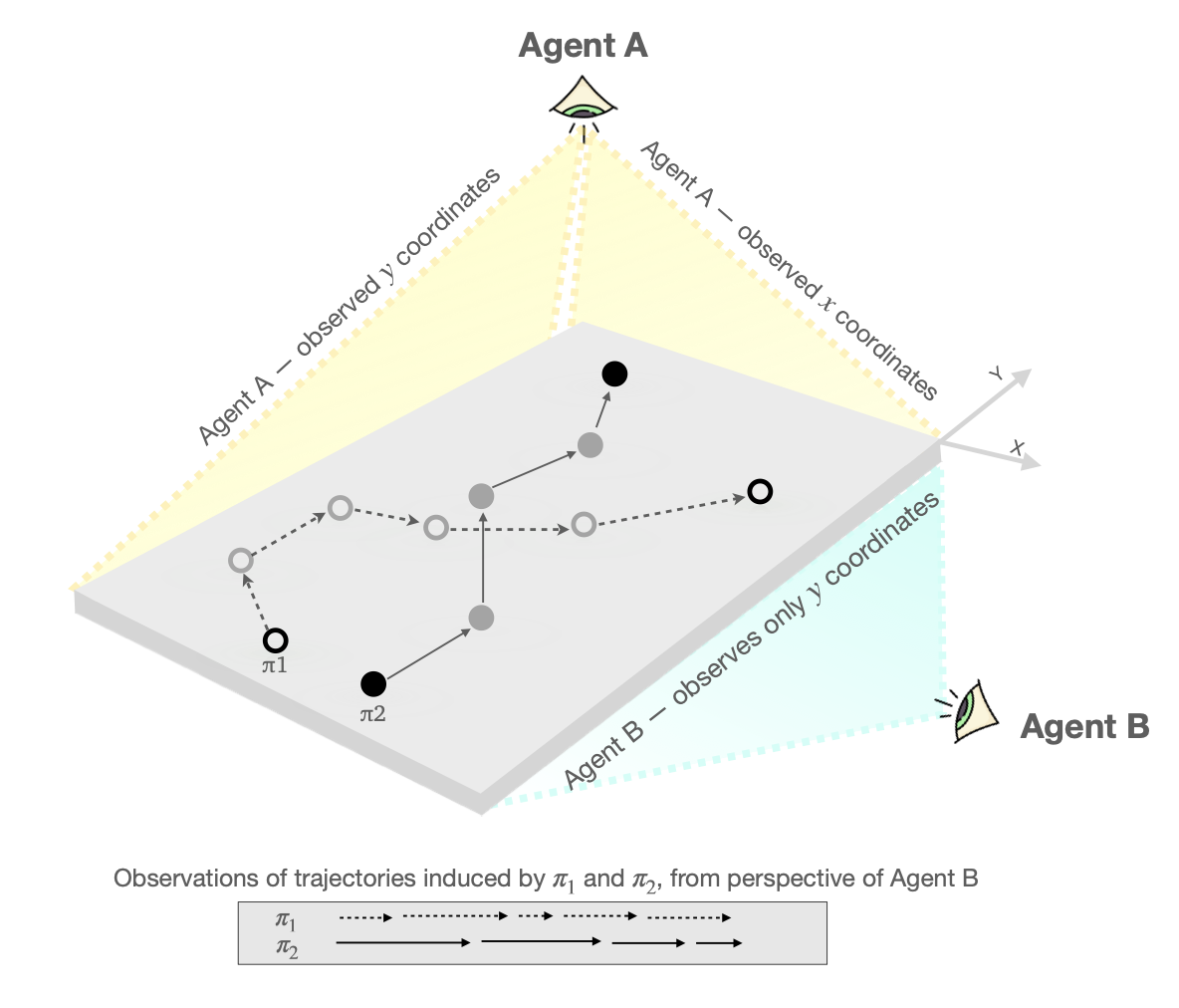
Models in reinforcement learning are often estimated from offline data, which in many real-world scenarios is subject to partial observability. In this work, we study the challenges that emerge from using models estimated from partially-observable offline data for policy evaluation. Notably, these models must be defined in conjunction with the data-collecting policy. To address this issue, we introduce a method for model estimation that incorporates importance weighting in the model learning process. The off-policy samples are reweighted to be reflective of their probabilities under a different policy, such that the resultant model is a consistent estimator of the off-policy model and provides consistent off-policy estimates of the expected return. This is a crucial step towards the reliable and responsible use of models learned under partial observability, particularly in scenarios where inaccurate policy evaluation can have catastrophic consequences. We empirically demonstrate the efficacy of our method and its resilience to common approximations such as weight clipping on a range of domains with diverse types of partial observability.
|
|
Off-Dynamics Reinforcement Learning: Training for Transfer with Domain Classifiers
Ben Eysenbach*,
Shreyas Chaudhari*,
Swapnil Asawa*,
Ruslan Salakhutdinov,
Sergey Levine.
*Equal contribution
The Ninth International Conference on Learning Representations (ICLR 2021)
Abstract | Paper
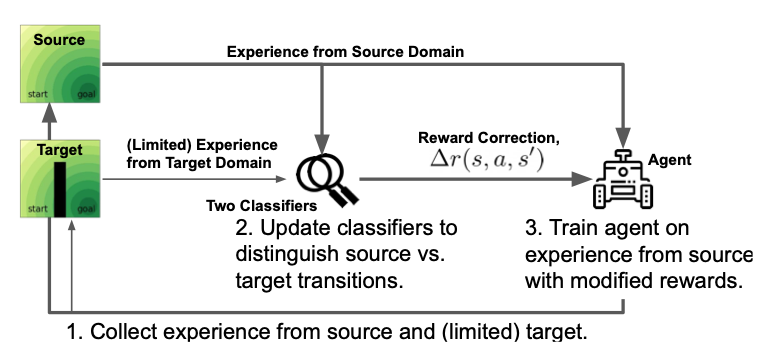
We propose a simple, practical, and intuitive approach for domain adaptation in reinforcement learning. Our approach stems from the idea that the agent's experience in the source domain should look similar to its experience in the target domain. Building off of a probabilistic view of RL, we formally show that we can achieve this goal by compensating for the difference in dynamics by modifying the reward function. This modified reward function is simple to estimate by learning auxiliary classifiers that distinguish source-domain transitions from target-domain transitions. Intuitively, the modified reward function penalizes the agent for visiting states and taking actions in the source domain which are not possible in the target domain. Said another way, the agent is penalized for transitions that would indicate that the agent is interacting with the source domain, rather than the target domain. Our approach is applicable to domains with continuous states and actions and does not require learning an explicit model of the dynamics. On discrete and continuous control tasks, we illustrate the mechanics of our approach and demonstrate its scalability to high-dimensional tasks.
|
|
Multi-Armed Bandits with Correlated Arms
Samarth Gupta,
Shreyas Chaudhari,
Gauri Joshi,
Osman Yağan.
IEEE Transactions on Information Theory 2021
Theoretical Foundations of RL Workshop at ICML 2020
Abstract | Paper
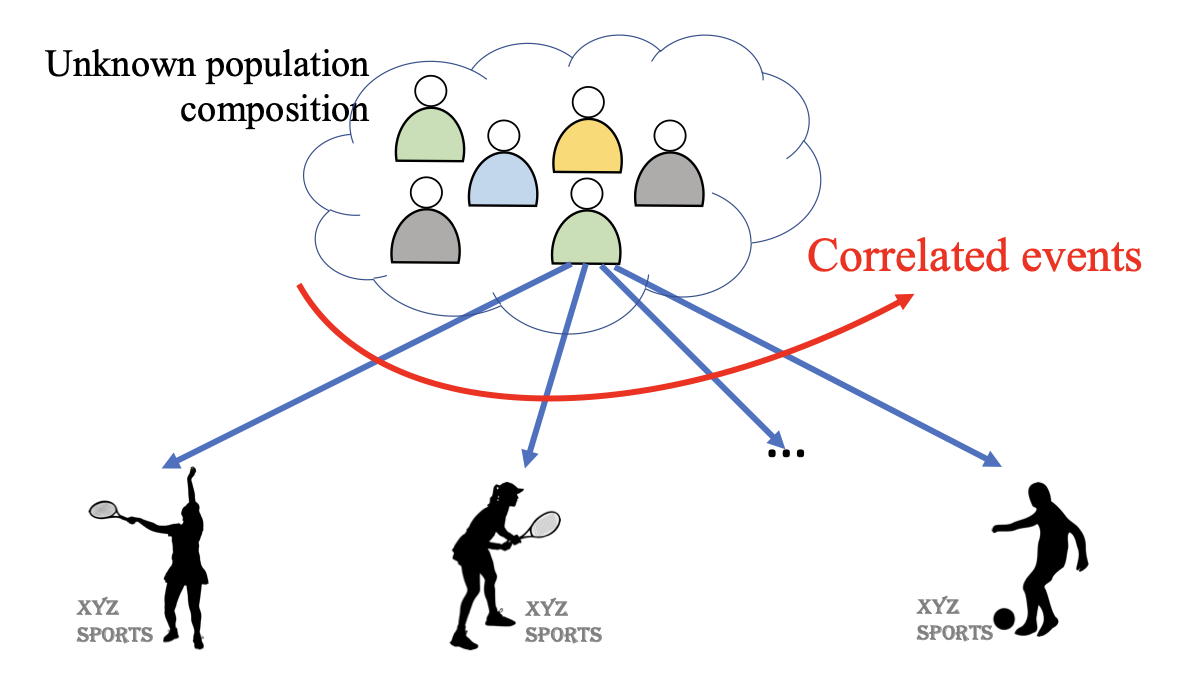
We consider a multi-armed bandit framework where the rewards obtained by pulling different arms are correlated. We develop a unified approach to leverage these reward correlations and present fundamental generalizations of classic bandit algorithms to the correlated setting. We present a unified proof technique to analyze the proposed algorithms. Rigorous analysis of C-UCB (the correlated bandit version of Upper-confidence-bound) reveals that the algorithm ends up pulling certain sub-optimal arms, termed as non-competitive, only O(1) times, as opposed to the O(log T) pulls required by classic bandit algorithms such as UCB, TS etc. We present regret-lower bound and show that when arms are correlated through a latent random source, our algorithms obtain order-optimal regret. We validate the proposed algorithms via experiments on the MovieLens and Goodreads datasets, and show significant improvement over classical bandit algorithms.
|
|
A Unified Approach to translate Classical Bandit Algorithms to the Structured Bandit Setting
Samarth Gupta,
Shreyas Chaudhari,
Subhojyoti Mukherjee,
Gauri Joshi,
Osman Yağan.
IEEE Journal on Selected Areas of Information Theory: Estimation and Inference 2021
IEEE ICASSP 2021
Abstract | Paper
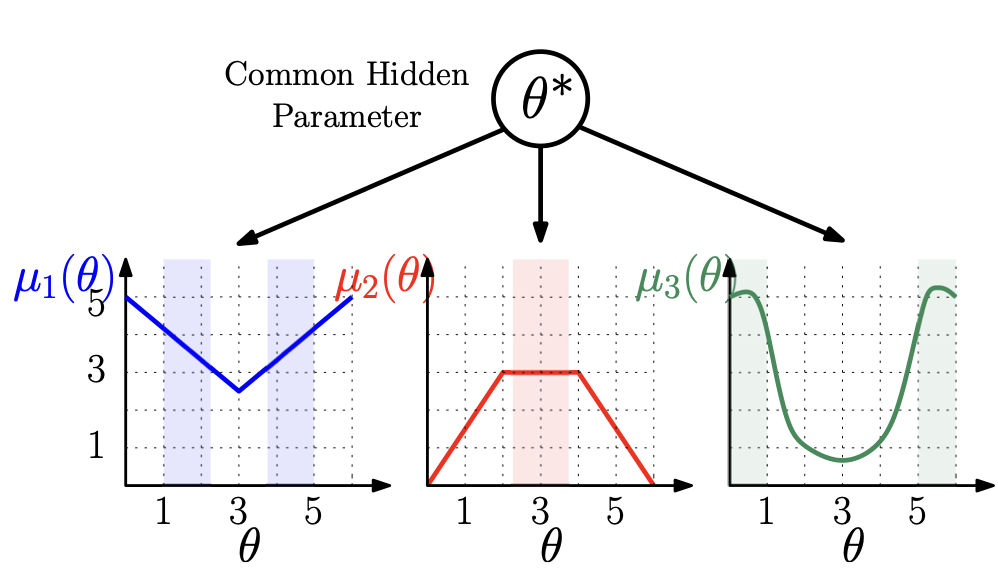
We consider a finite-armed structured bandit problem in which mean rewards of different arms are known functions of a common hidden parameter θ*. Since we do not place any restrictions of these functions, the problem setting subsumes several previously studied frameworks that assume linear or invertible reward functions. We propose a novel approach to gradually estimate the hidden θ* and use the estimate together with the mean reward functions to substantially reduce exploration of sub-optimal arms. This approach enables us to fundamentally generalize any classic bandit algorithm including UCB and Thompson Sampling to the structured bandit setting. We prove via regret analysis that our proposed UCB-C algorithm (structured bandit versions of UCB) pulls only a subset of the sub-optimal arms O(logT) times while the other sub-optimal arms (referred to as non-competitive arms) are pulled O(1) times. As a result, in cases where all sub-optimal arms are non-competitive, which can happen in many practical scenarios, the proposed algorithms achieve bounded regret. We also conduct simulations on the Movielens recommendations dataset to demonstrate the improvement of the proposed algorithms over existing structured bandit algorithms.
|
